预测性维护怎么玩之实践篇
编辑导语: 引言 去年写过一篇《预测性维护怎么玩之科普篇》,为大家介绍了预测性维护的基础知识。正所谓,纸上得来终觉浅,欲知此事要躬行。看书看资料、google、百度总是会有收获的,但是,正如之前一位前辈说…
引言
去年写过一篇《预测性维护怎么玩之科普篇》,为大家介绍了预测性维护的基础知识。正所谓,纸上得来终觉浅,欲知此事要躬行。看书看资料、google、百度总是会有收获的,但是,正如之前一位前辈说的那样,只有你真正沉到项目里,水平才会有实质性的提高。最近就有幸获得了这样一个实操的机会,作为业务分析师,参与到了一个西部地区某离散制造业企业的预测性维护试点项目中。
下面把项目中的实践过程以及一些感悟与大家做个分享。
项目历程
背景
客户方是一家比较有前瞻性的民营企业,在之前的两化融合、两化深度融合等阶段,在国家和地方政府的支持下,已经开展了不少的自动化改造、信息化建设等项目。应该说,该企业的底子还是不错的,以我的经验来看,该企业在车间层面的信息化程度甚至可以和烟草、汽车等行业的龙头企业相提并论。
近些年,受智能制造大趋势的影响,各业务部门纷纷摩拳擦掌、跃跃欲试,准备在预测性维护领域小试牛刀。
这里有必要澄清一点,预测性维护和当前工业现场广泛使用的很多专家系统还是有所区别的。专家系统往往是设备厂商提供的,主要是基于机理模型,是根据设备机理,展现某些故障与某些状态信息的因果关系,本质上属于基于状态的维修(CBM,Condition-based maintenance)。预测性维护是基于数理模型,从统计学角度展现故障与某些状态信息的关联关系。
场景选择
做的决心已定,那么接下来就是选场景。
对于预测性维护来说,建模方法千万条,选对场景第一条。
那么,如何选择好的场景呢,或者,一个好场景要具备哪些条件?
- 熟悉设备机理,能够识别出被预测量(停机故障)的影响因素(维度)。毕竟,我们的数据分析工程师擅长的机器学习技术,对设备的机理很难短时间内掌握,因此,需要生产现场对设备相对熟悉的工作人员指出造成设备停机故障的可能影响因素,例如电控系统中的电信号信息、机械结构的热变形等。这些信息都将成为特征工程的重要输入。
- 数据质量要好。对于工业现场来说,数据质量的要求可以概括为两个词——准确,连续。首先,准确指的是,不能有过多的干扰噪声,以及不准确的记录(比如手工录入到系统中的停机停台数据)。其次,连续指的是,对于故障发生前的一定时间窗口内的影响数据(如电流,电压等),最理想的状况是其能够以连续量的形式呈现,即完整地展示设备运行的全过程。而不是仅仅能够获取个别超过阈值的报警信息。
- 具有足够的样本数量。模型是需要用样本来训练的,这里的样本指的就是设备所发生的故障信息。一台从没发生故障,或者很少发生故障的设备,是不适合做预测性维护的。因为对于机器学习这项技术,模型是需要训练的,它一定要从过去众多的故障样本中学习,才能够建立模型,它还无法做到像人类一样去推理和抽象
- 能够复用的模型。如果只针对一个车间的某一台或几台设备的停机故障进行建模,而该模型又不能复用到更大的范围内,那么,投入产出比可能就会比较低。
实施过程
应用机器学习技术进行预测性维护建模的具体技术实现过程,大家请参考《预测性维护怎么玩之科普篇》,实际项目中的过程与文中所描述的差不多,此处不再赘述。
下面仅就实施过程中遇到的最大的困难——数据质量问题,与大家分享,希望能够对以后的预测性维护项目的开展有所借鉴。
数据质量的问题主要体现在以下几个方面:
- 数据不准确。作为被预测量的停机故障数据,缺少准确全面的记录。在生产现场,上述记录是由设备运维人员手工录入到SAP系统中,因此,在故障发生时间方面,很难非常精确。而故障发生的时间点是用来进行建模的重要数据维度,数据分析工程师将根据此时间点之前一定时间窗口的众多自变量(故障影响因素)的数据进行特征的提取,对模型的建立至关重要。因此,如果对于故障发生的时间没有准确记录的话,势必会影响模型的最终精度。此外,人工的记录还会造成遗漏。所以,最理想的情况是,有系统能够根据设备的运行状态对设备的故障信息进行准确记录,即完全自动化的记录方式。
- 数据维度的缺失。依据设备机理,不同维度的数据都会对设备故障的发生产生影响,如电压、电流、振动等等。这些维度的数据都是特征工程的重要输入。与设备故障相关的数据种类越多,模型的准确率才能越高。但是,目前工业现场的数据种类是有限的,有很多数据在上位机中或者在设备中,由于开放性的原因,只能手动查看,却无法提取出来。这样的情况势必会影响模型的准确性。
- 缺少足够数量的历史数据。模型是需要样本来训练的,因此,样本的数量是多多益善。工业现场虽然有很多上位机系统做数据采集,但是,大多不会做长时间的存储,这也造成了训练样本的缺乏。
总结
现阶段,做智能制造的广大厂商,大多是平台方案很多,但是落地案例寥寥。说明,尽管现在智能制造的概念满天飞,但是真正想落地,还是有不小的困难的。并且要想产生业务价值,有非常好的投入产出比,就更加困难了。
应该说,这个预测性维护项目,作为一个试点,是具有很大意义的。
技术
这个试点项目在技术方面的价值在于,将开源的信息集成技术应用于工业现场,打通IT与OT,完成OT层面的数据采集、IT层面的信息集成,并应用智能化的技术——机器学习技术对数据进行分析,即预测性建模。
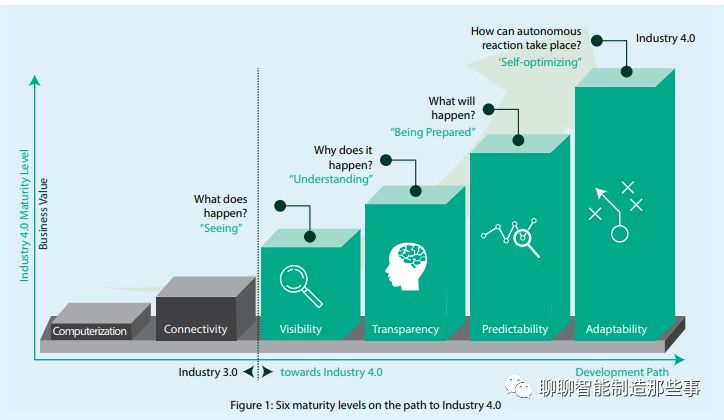
证明上述技术在工业现场的适用性。也就是对应于工业4.0六个成熟度水平中的第二阶段connectivity和第五阶段的predictablity所发挥的作用。
文化
在文化方面,总结成一句话就是,要有向数据中要价值的意识。
以往,现场工作人员往往将注意力集中在设备的性能上,忽略了对其数据的要求,如数据接口的开放性、数据种类的全面性等。
通过这个试点项目,客户方的现场工作人员已经基本建立起了数据分析的意识,而在过往的工作中,制造业企业的员工往往对数据分析不够重视,也不能够理解数据分析在实际工作中的价值。
我们的制造业的一线从业者如果能够主动学习机器学习等数据分析技术,在日常工作中有意识地应用这些技术对现有数据进行分析,或者,对当前生产现场的数据情况(如数据不准确,重要数据缺失)进行识别与改进,将有助于生产现场设备运维等工作效率的提升、成本的降低。
有了这样的数据分析意识,现场工程师就会去主动思考,我的设备故障可能和哪些因素有关系,温度、振动还是电机的发热等等,这些影响因子的数据如何能够获取。如果我的现有设备在这些方面的数据有所缺乏,包括缺乏实时数据的采集、历史数据的保存,那么,在未来,在采购新的设备的时候就一定要将上述数据的获取作为技术要求,来与设备厂商进行洽谈,写入设备的采购合同中。
推而广之,通过智能化的方式来向数据中要价值,是所有行业未来发展的必经之路。这不仅是制造业的未来,也是各行各业的未来。只不过,在相关技术(如物联网、机器学习等)的应用方面,制造业难度更大,成本更高,因此,在短期之内,爆发式的发展不具备条件。
生态
目前,开展预测性维护项目,工厂最头痛的就是如何从现有设备中获取数据,已经在现场使用的设备很多都没有数据采集的接口,或者明明能够看到数据,但是采集不出来,比如设备的触摸屏上显示的曲线等等。这时再去和设备厂商谈接口开放,往往周期就比较长,设备厂商也不愿意做这样的开放工作。这也涉及到数据尊严的问题——明明工厂自己是数据的产生者,但是却不能利用自己的数据。
这次项目现场的情况就逼得我们只能通过旁门左道获取设备中的数据。
但是,在项目进行的过程中,客户已经意识到数据质量的问题,已经开始借助高层的力量与众多的设备厂商进行洽谈,探讨数据开放的问题,希望能够与设备厂商建立生态,共同推进智能制造的进程。
注:客户方同时也在寻求第三方的力量来获取设备中的运行数据。但是最为稳妥的做法还是通过设备厂商来实现数据的获取,通过第三方的手段,如增加板卡之类的方式,往往涉及到一定的设备改造,会对设备的稳定运行带来风险。
结语
这样的试点项目做下来,甲乙双方的项目组成员都深深地体会到了其中的困难,也会在未来开展类似项目时更为慎重。
诚然,现阶段,在国内大部分的工业现场,并不能够完全具备开展类似项目的条件。
但是,是否因为这样的现状,我们就暂时放弃向智能化方向的尝试了呢?
这里摘抄哈佛商业评论中的《开辟式创新》中的一段话:如果能摆脱认为某些事情不可能实现的传统思维,重新思考能做到什么,就可以开始创造真正有力的东西,而且拥有改变世界的潜力
我认为,对于智能制造,应该立足于当下的条件,看看能做什么,以这些点状的项目(试点)来带动“面”,使制造业的决策者认识到企业中某些条件的缺乏,促使他们加快补齐这些基础。这种方式会更有方向性,更有动力。因此,当务之急还是要想想基于现有的条件能做些什么。
不能等条件都具备了再去尝试智能化的应用,如果那样的话,恐怕永远都无法确切地知道我们究竟需要哪些条件。
最近更新于 2022-05-14, 由 猿小六 于 2021-10-20 发布, 已阅 1139 次。